
Duration: 01.01.2023-31.12.2023
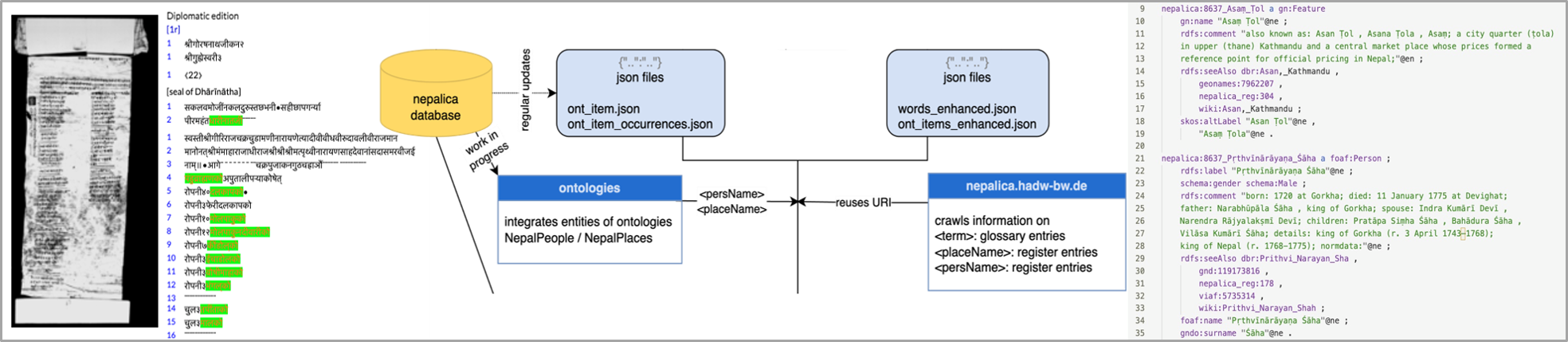
Editions as linked data
Scientific text editions pose a major challenge due to a variety of factors with regard to secondary, overarching evaluation and their reusability. These include the compilation of content as well as the evaluation and safeguarding of the collected data. The challenges include
- different temporal and geographical orientations of the research content
- different languages and language levels
- different writing systems
- Presentation in different combinations of edited text, translation, facsimiles, etc.
- Digital data is available in different system architectures and data models
- Changeability of the collected data during the term of the edition ‘hot data’ (only the long-term archiving of the data after the end of the project ‘cold data’ guarantees the immutability of the data).
The long-term accessibility of research data is therefore an essential element of scientific research.
The Project
The ‘edition2LD’ project is working on a solution for data curation that makes heterogeneous research data accessible in the long term and across the boundaries listed above. This must be flexible enough for the heterogeneity of the data and at the same time stable enough for a long-term perspective. For the solution, the edition2LD project follows the paradigm of Linked Data (LD) and the integration of data into the Semantic Web.
Use case as ‘best practice’
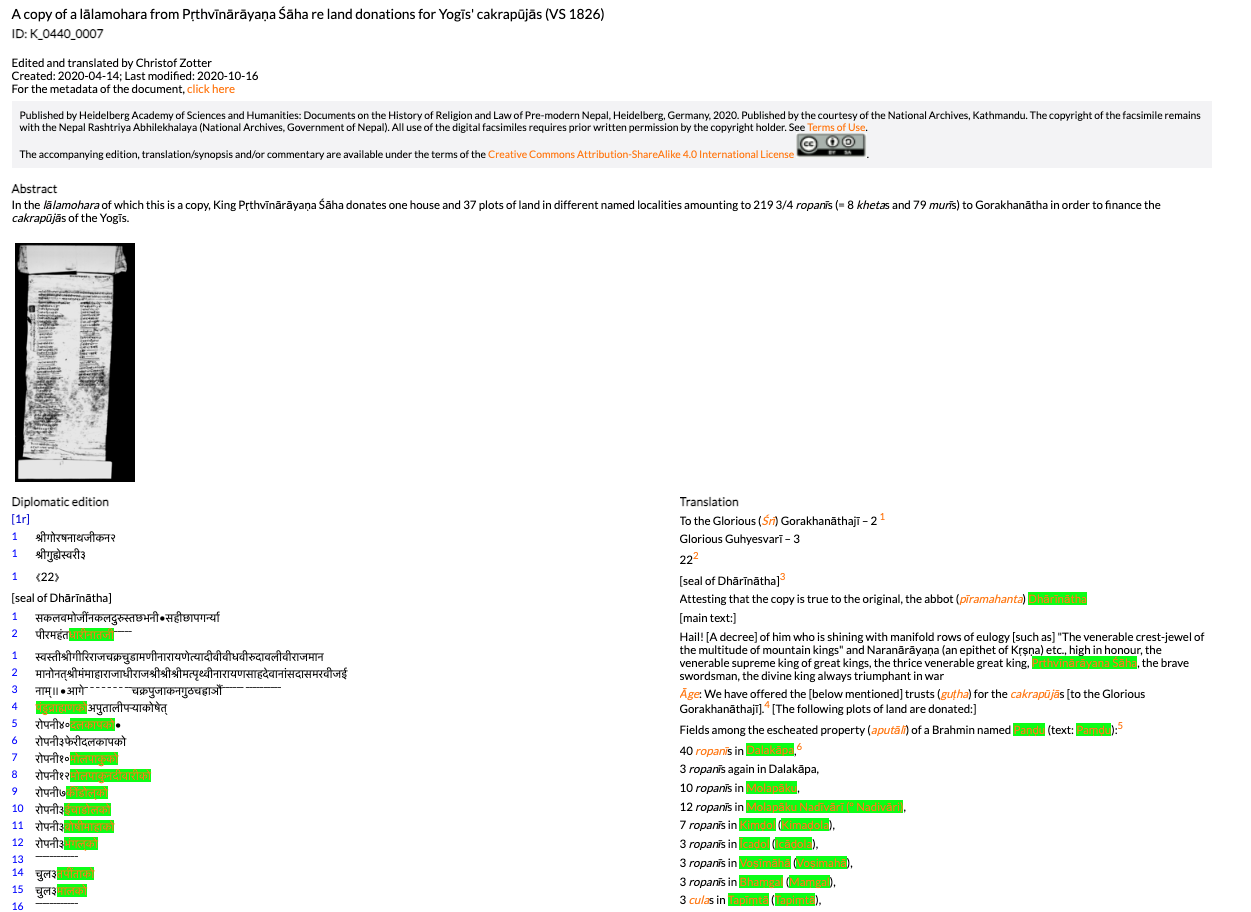
In order to develop the workflow for linked data (LD) modelling, the project chooses the editions of the HAdW research centre „Religions- und rechtsgeschichtliche Quellen des vormodernen Nepal“ (Nepal-FS) as a use case. The research centre produces digital editions of the Nepali texts (in Devanagari script) including facsimiles, English translations (in Latin script), commentaries and index entries (persons, places, specialist terms).
It is published on nepalica.hadw-hw.de and on the pages of the Heidelberg University Library (see e.g. https://digi.hadw-bw.de/view/dna_0001_0005) with a DOI.
Approach
The workflow for LD modelling should be generic enough to prepare for future transferability to other projects. At the same time, it should be capable of transferring data into RDF in batches - repeatedly triggered - and thus responding to the major challenge of variable ‘hot data’. When developing the automated mapping processes, it is therefore immensely important to minimise the step of manual post-processing, ideally so that it only has to be carried out once.
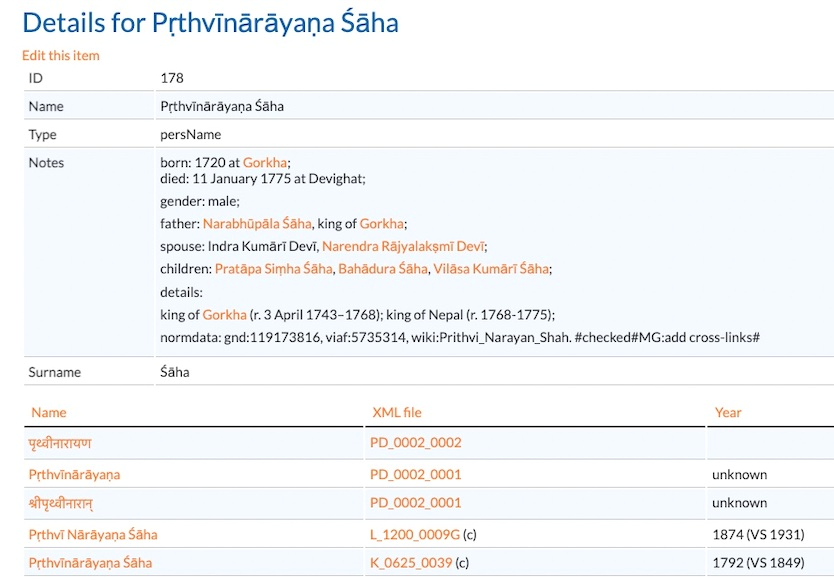
The project focuses on modelling the information units ‘text’, ‘English translation’, named entities (personal and place names) and specialist terms as well as metadata. For the modelling of named entities, the project can draw on register entries from the Nepal-FS, some of which already contain further references to standard data repositories and encyclopaedic resources.
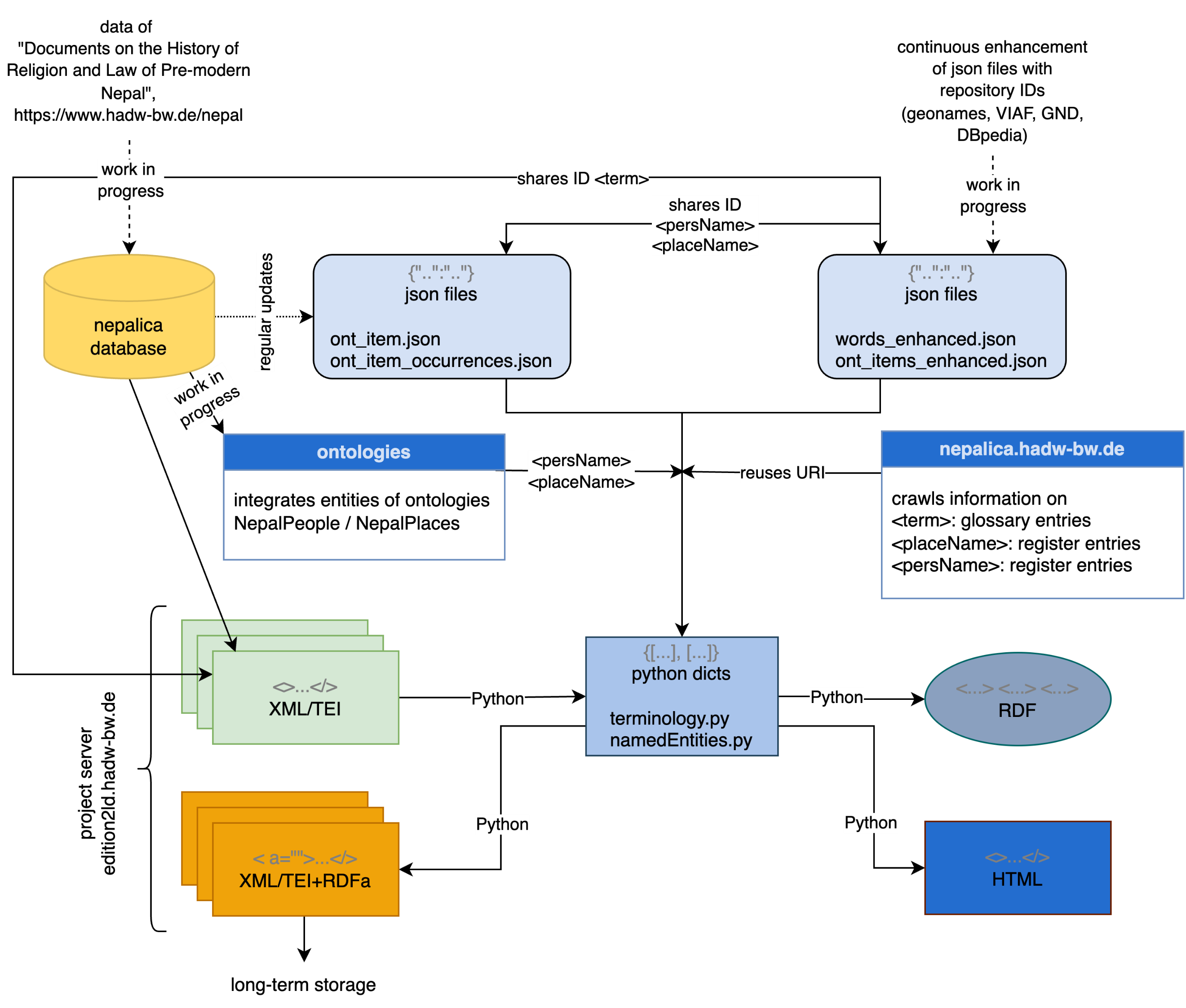
The vocabularies, ontologies and repositories used for modelling are those already established as standards: RDFS, SKOS, Gemeinsame Normdatei GND, VIAF, DBpedia, GeoNames, FOAF. In addition, the LD modelling adds links to instances of two ontologies for historical names of people and places in Nepal (NepalPeople and NepalPlaces, see Tittel 2022*), which are being developed using the research data of the Nepal-FS.
The data sources are
- the database of the Nepal-FS
- Files with further information
- Information that is integrated into the pipeline from the register and glossary entries via web crawling
- NepalPeople and NepalPlaces ontologies: Python scripts compare the modelled data with the NepalPeople and NepalPlaces entries and integrate links to their instances if necessary.

As of today [September 2023], the modelling of the named entities and terms is 90% complete, the modelling of the units ‘English translation’, ‘Nepali edition’ and the metadata is in progress.
The project "Sprachdatenbasierte Modellierung von Wissensnetzen in der mittelalterlichen Romania – ALMA" (internal link), which started as an inter-academic project of the HAdW, BAdW and AdW Mainz on 1 August 2022 as part of the Academies' Programme, follows an approach that is already based on linked data throughout. As ALMA compiles text editions (here of medieval legal and medical texts), this database can also be used well for an edition2LD approach.
Publications
Svoboda-Baas, Dieta/Tittel, Sabine: Text+Plus, #04: Modellierung von Texteditionen als Linked Data (edition2LD), in: Text+ Blog, 18.12.2023, https://textplus.hypotheses.org/8723.
*Tittel, Sabine. "Towards an Ontology for Toponyms in Nepalese Historical Documents", in: Proceeding of the Workshop on Resources and Technologies for Indigenous, Endangered and Lesser-resourced Languages in Eurasia within the 13th Language Resources and Evaluation Conference, Marseille, June 2022, 2022, Marseille (European Language Resource Association - ELRA), S. 7-16.